
本文轉(zhuǎn)自知乎作者:CVHub
導(dǎo)讀
眾所周知,視覺系統(tǒng)對于理解和推理視覺場景的組成特性至關(guān)重要。這個領(lǐng)域的挑戰(zhàn)在于對象之間的復(fù)雜關(guān)系、位置、歧義、以及現(xiàn)實(shí)環(huán)境中的變化等。作為人類,我們可以很輕松地借助各種模態(tài),包括但不僅限于視覺、語言、聲音等來理解和感知這個世界。現(xiàn)如今,隨著 Transformer 等關(guān)鍵技術(shù)的提出,以往看似獨(dú)立的各個方向也逐漸緊密地聯(lián)結(jié)到一起,組成了“多模態(tài)”的概念。
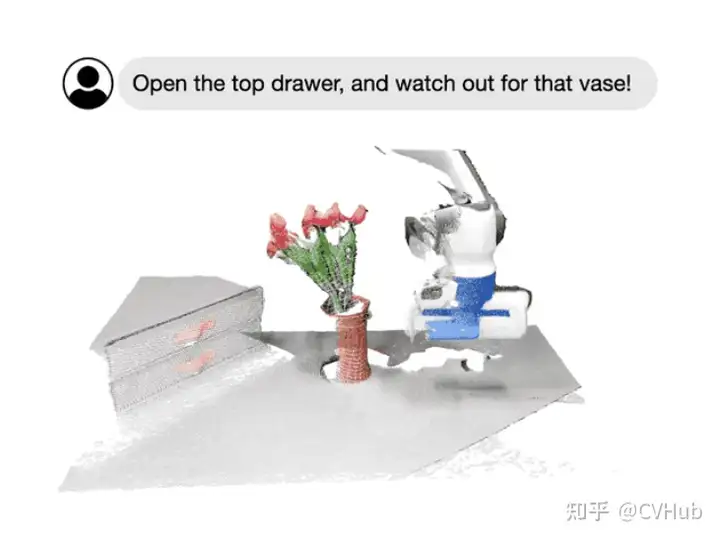
今天,我們主要圍繞Foundational Models,即基礎(chǔ)模型這個概念,向大家全面闡述一個嶄新的視覺系統(tǒng)。例如,通過 SAM,我們可以輕松地通過點(diǎn)或框的提示來分割特定對象,而無需重新訓(xùn)練;通過指定圖像或視頻場景中感興趣的區(qū)域,我們可以與模型進(jìn)行多輪針對式的交互式對話;再如李飛飛團(tuán)隊最新展示的科研成果所示的那樣,我們可以輕松地通過語言指令來操作機(jī)器人的行為。
該術(shù)語首次由Bommasani等人在《Stanford Institute for Human-Centered AI》中引入。基礎(chǔ)模型定義為“通過自監(jiān)督或半監(jiān)督方式在大規(guī)模數(shù)據(jù)上訓(xùn)練的模型,可以適應(yīng)其它多個下游任務(wù)”。具體地,我們將一起討論一些典型的架構(gòu)設(shè)計,這些設(shè)計結(jié)合了不同的模態(tài)信息,包括視覺、文本、音頻;此外,我們還將著重討論不同的訓(xùn)練目標(biāo),如對比式學(xué)習(xí)和生成式學(xué)習(xí)。隨后,關(guān)于一些主流的預(yù)訓(xùn)練數(shù)據(jù)集、微調(diào)機(jī)制以及常見的提示模式,我們也將逐一介紹。
最后,希望通過今天的學(xué)習(xí)讓大家對基礎(chǔ)模型在計算機(jī)視覺領(lǐng)域的發(fā)展情況,特別是在大規(guī)模訓(xùn)練和不同任務(wù)之間的適應(yīng)性方面的最新進(jìn)展有一個大致的認(rèn)知。共勉。
需要完整 PDF 版本請?zhí)砑游⑿盘? cv_huber,備注“視覺大模型”即可領(lǐng)取!
背景介紹
近年來,基礎(chǔ)模型取得了顯著的成功,特別是通過大型語言模型(LLMs),主要?dú)w因于數(shù)據(jù)和模型規(guī)模的大幅擴(kuò)展。例如,像GPT-3這樣的十億參數(shù)模型已成功用于零/少樣本學(xué)習(xí),而無需大量的任務(wù)特定數(shù)據(jù)或模型參數(shù)更新。與此同時,有5400億參數(shù)的Pathways Language Model(PaLM)在許多領(lǐng)域展現(xiàn)了先進(jìn)的能力,包括語言理解、生成、推理和與代碼相關(guān)的任務(wù)。
反觀視覺領(lǐng)域,諸如CLIP這樣的預(yù)訓(xùn)練視覺語言模型在不同的下游視覺任務(wù)上展現(xiàn)了強(qiáng)大的零樣本泛化性能。這些模型通常使用從網(wǎng)絡(luò)收集的數(shù)百上千萬圖像-文本對進(jìn)行訓(xùn)練,并提供具有泛化和遷移能力的表示。因此,只需通過簡單的自然語言描述和提示,這些預(yù)訓(xùn)練的基礎(chǔ)模型完全被應(yīng)用到下游任務(wù),例如使用精心設(shè)計的提示進(jìn)行零樣本分類。
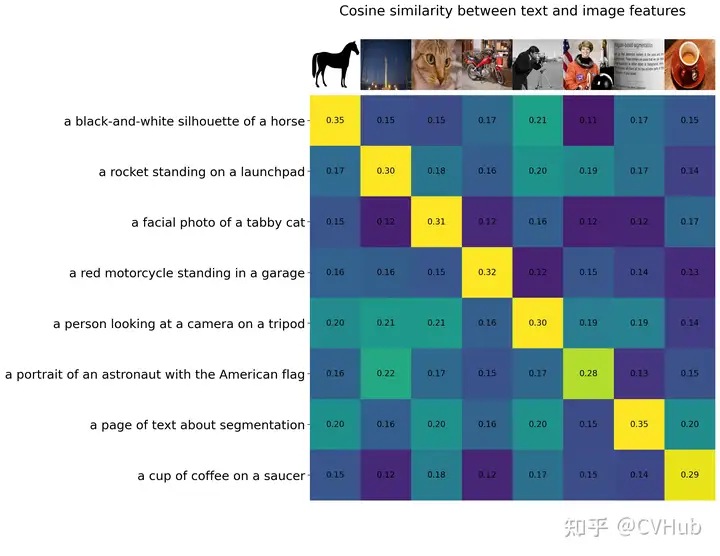
除了此類大型視覺語言基礎(chǔ)模型外,一些研究工作也致力于開發(fā)可以通過視覺輸入提示的大型基礎(chǔ)模型。例如,最近 META 推出的 SAM 能夠執(zhí)行與類別無關(guān)的分割,給定圖像和視覺提示(如框、點(diǎn)或蒙版),指定要在圖像中分割的內(nèi)容。這樣的模型可以輕松適應(yīng)特定的下游任務(wù),如醫(yī)學(xué)圖像分割、視頻對象分割、機(jī)器人技術(shù)和遙感等。

當(dāng)然,我們同樣可以將多種模態(tài)一起串起來,組成更有意思的管道,如RAM+Grounding-DINO+SAM:
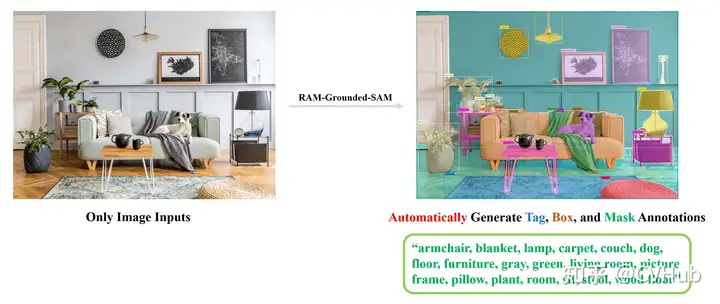
這里我們用 RAM 提取了圖像的語義標(biāo)簽,再通過將標(biāo)簽輸入到 Grounding-DINO 中進(jìn)行開放世界檢測,最后再通過將檢測作為 SAM 的提示分割一切。目前視覺基礎(chǔ)大模型可以粗略的歸為三類:
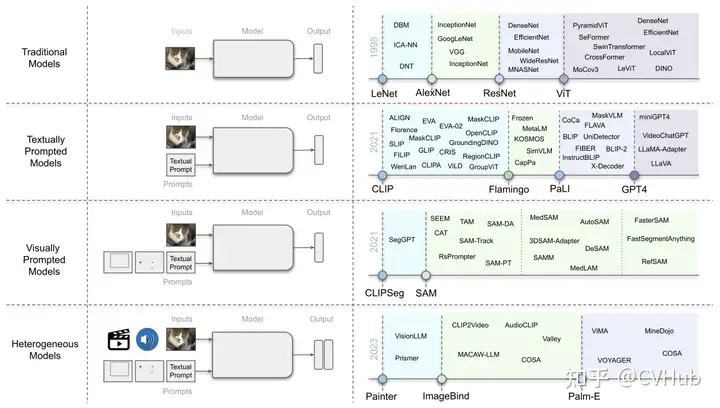
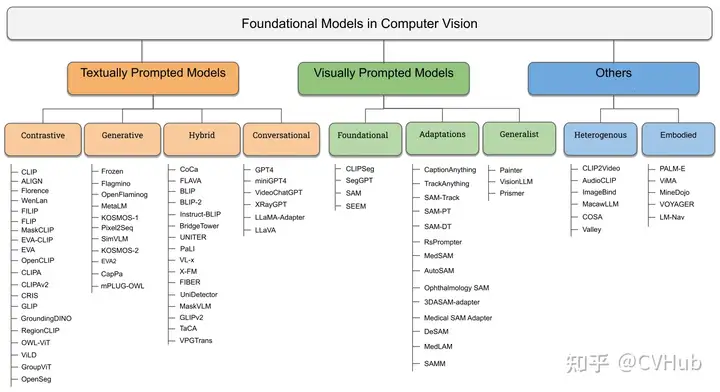
textually prompted models, e.g., contrastive, generative, hybrid, and conversational;visually prompted models, e.g., SAM, SegGPT;heterogeneous modalities-based models, e.g., ImageBind, Valley.
基礎(chǔ)架構(gòu)
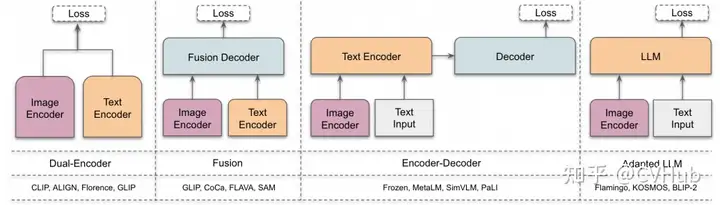
雙編碼器架構(gòu):其中,獨(dú)立的編碼器用于處理視覺和文本模態(tài),這些編碼器的輸出隨后通過目標(biāo)函數(shù)進(jìn)行優(yōu)化。
融合架構(gòu):包括一個額外的融合編碼器,它獲取由視覺和文本編碼器生成的表示,并學(xué)習(xí)融合表示。
編碼器-解碼器架構(gòu):由基于編碼器-解碼器的語言模型和視覺編碼器共同組成。
自適應(yīng) LLM 架構(gòu):利用大型語言模型(LLM)作為其核心組件,并采用視覺編碼器將圖像轉(zhuǎn)換為與 LLM 兼容的格式(模態(tài)對齊)。
目標(biāo)函數(shù)
對比式學(xué)習(xí)
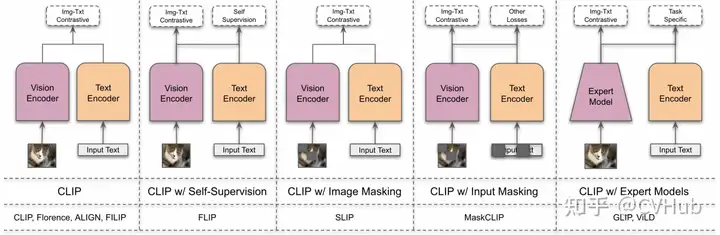
為了從無標(biāo)簽的圖像-文本數(shù)據(jù)中學(xué)習(xí),CLIP 中使用了簡單的圖像-文本對比(ITC)損失來通過學(xué)習(xí)正確的圖像-文本配對來學(xué)習(xí)表示。此外還有圖像-文本匹配(ITM)損失,以及包括簡單對比式學(xué)習(xí)表示(SimCLR)和 ITC 損失的變體(如 FILIP Loss、TPC Loss、RWA、MITC、UniCL、RWC 損失)等其他對比損失。
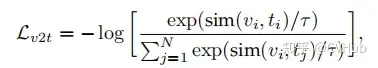
這里 表示溫度系數(shù)。因此我們可以將 簡單表示為 . 可以看出,本質(zhì)上還是在計算圖像與文本之間的相似度得分,比如常見的余弦相似性。
生成式學(xué)習(xí)
生成目標(biāo)包括以下幾種典型的損失:
掩碼語言建模(MLM)損失
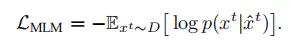
語言建模(LM)損失
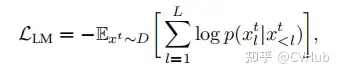
標(biāo)準(zhǔn)字幕(Cap)損失
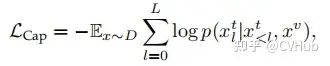
以及 Flamingo Loss、Prefix Language Modeling, PrefixML 等。從上述公式我們也可以很容易看出,生成式 AI 本質(zhì)還是條件概率模型,如 Cap 損失便是根據(jù)上一個已知 token 或 圖像來預(yù)測下一個 token。
預(yù)訓(xùn)練
預(yù)訓(xùn)練數(shù)據(jù)集
如上所述,現(xiàn)代視覺-語言基礎(chǔ)模型的核心是大規(guī)模數(shù)據(jù),大致可分為幾類:
圖像-文本數(shù)據(jù):例如
CLIP使用的WebImageText等,這些數(shù)據(jù)通常從網(wǎng)絡(luò)抓取,并經(jīng)過過濾過程刪除噪聲、無用或有害的數(shù)據(jù)點(diǎn)。部分偽標(biāo)簽數(shù)據(jù):由于大規(guī)模訓(xùn)練數(shù)據(jù)在網(wǎng)絡(luò)上不可用,收集這些數(shù)據(jù)也很昂貴,因此可以使用一個好的教師將圖像-文本數(shù)據(jù)集轉(zhuǎn)換為掩碼-描述數(shù)據(jù)集,如
GLIP和SA-1B等。數(shù)據(jù)集組合:有些工作直接將基準(zhǔn)視覺數(shù)據(jù)集組合使用,這些作品組合了具有圖像-文本對的數(shù)據(jù)集,如字幕和視覺問題回答等。一些工作還使用了非圖像-文本數(shù)據(jù)集,并使用基于模板的提示工程將標(biāo)簽轉(zhuǎn)換為描述。
微調(diào)
微調(diào)主要用于三個基本設(shè)置:
提高模型在特定任務(wù)上的性能(例如開放世界物體檢測,
Grounding-DINO);提高模型在某一特定能力上的性能(例如視覺定位);
指導(dǎo)調(diào)整模型以解決不同的下游視覺任務(wù)(例如
InstructBLIP)。
首先,許多工作展示,即使只采用線性探測,也可以提高模型在特定任務(wù)上的性能。因此,特定任務(wù)的數(shù)據(jù)集(例如ImageNet)是可以用來改善預(yù)訓(xùn)練模型的特定任務(wù)性能。其次,一些工作已經(jīng)利用預(yù)訓(xùn)練的視覺語言模型,通過在定位數(shù)據(jù)集上微調(diào)模型來進(jìn)行定位任務(wù)。
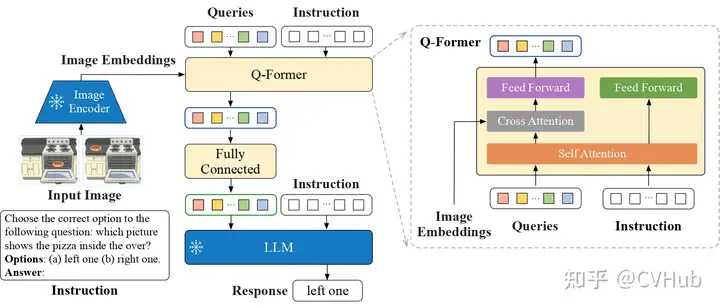
例如,谷歌的一篇 OVD 工作 OWL-ViT,將 CLIP 預(yù)訓(xùn)練模型去掉 Token Pooling+projection 和 Image projection,加上一個新的 Linear Projection 作為分類頭與文本進(jìn)行匹配,學(xué)習(xí)出每個 Patch 的語義信息。此外在將 Patch 的表征經(jīng)過 MLP head 回歸出相應(yīng)檢測狂。通過 Patch 的語義特征與 BBox 的位置最終獲得目標(biāo)檢測框。最后,像 InstructBLIP 則將視覺數(shù)據(jù)集轉(zhuǎn)換為指導(dǎo)調(diào)整數(shù)據(jù)集,使視覺語言模型能夠用于下游任務(wù)。
提示工程
提示工程主要是搭配大型語言模型(LLMs)一起使用,使它們能夠完成某些特定的任務(wù)。在視覺語言模型或視覺提示模型的背景下,提示工程主要用于兩個目的:
將視覺數(shù)據(jù)集轉(zhuǎn)換為圖像文本訓(xùn)練數(shù)據(jù)(例如,用于圖像分類的 CLIP),為基礎(chǔ)模型提供交互性
使用視覺語言模型進(jìn)行視覺任務(wù)。
大多數(shù)視覺數(shù)據(jù)集由圖像和相應(yīng)文本標(biāo)簽組成。為了利用視覺語言模型處理視覺數(shù)據(jù)集,一些工作已經(jīng)利用了基于模板的提示工程。在這種提示工程中,使用一組模板從標(biāo)簽生成描述。例如:
text_descriptions = [fThis is a photo of a {label} for label in cifar100.classes] text_tokens = clip.tokenize(text_descriptions).cuda() 這種額外的上下文有助于模型學(xué)習(xí),因此,這些文本提示可以在訓(xùn)練或評估期間被 VLM 所使用。下面讓我們一起了解下這三類視覺基礎(chǔ)模型。
需要完整 PDF 版本請?zhí)砑游⑿盘? cv_huber,備注“視覺大模型”即可領(lǐng)取!
基于文本提示的基礎(chǔ)模型
在本章節(jié)中,我們專注于探討依賴文本作為主要監(jiān)督來源的方法。這些文字提示模型大致分為三個主要類型,即基于不同的訓(xùn)練目標(biāo):對比學(xué)習(xí)、生成學(xué)習(xí)和混合方法。
基于對比學(xué)習(xí)的方法
首先,讓我們一起回顧下 CLIP 架構(gòu)及其衍生的變體:
CLIP 由 OpenAI 于 2021 年正式提出,其聯(lián)合訓(xùn)練圖像和文本編碼器以預(yù)測圖像與標(biāo)題在批量中的正確配對。CLIP 由圖像編碼器和文本編碼器組成。它們產(chǎn)生了N個圖像-文本對的多模態(tài)嵌入空間。通過對稱交叉熵?fù)p失來訓(xùn)練,以最小化N個正確圖像-文本對的嵌入的余弦相似度,并最大化N2-N個不正確對的余弦相似度。作者還從互聯(lián)網(wǎng)上策劃了4億圖像-文本對的數(shù)據(jù)集。在這樣的大規(guī)模數(shù)據(jù)集上訓(xùn)練時,表現(xiàn)非常出色,也激發(fā)了后續(xù)許多的工作。
此處我們集中探討兩類擴(kuò)展方法,包括通用模型的對比方法和視覺定位基礎(chǔ)模型的方法。
基于通用模型的對比方法
ALIGN 利用了一個超過10億個圖像-文本對的噪聲數(shù)據(jù)集,無須進(jìn)行昂貴的過濾或處理步驟即可在 Conceptual Captions 數(shù)據(jù)集中獲得。一個簡單的雙編碼器架構(gòu)學(xué)習(xí)使用對比性損失來對齊圖像和文本對的視覺和語言表示。結(jié)果表明,即便是這樣一個簡單的學(xué)習(xí)方案,只要數(shù)據(jù)庫夠大,便可以彌補(bǔ)它的噪聲,并最終得到 SOTA 結(jié)果。
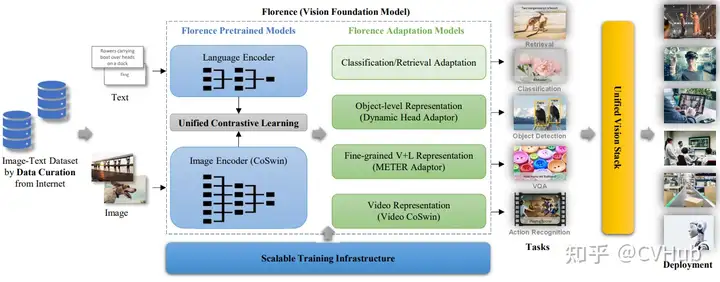
佛羅倫薩是微軟、OpenAI 等聯(lián)合提出的一個真正意義上的計算機(jī)視覺基礎(chǔ)模型,能夠處理不同的空間、時間和模態(tài)。它從CLIP樣的預(yù)訓(xùn)練開始,然后擴(kuò)展為具有三個不同適配器頭的每個空間。弱弱的說一句,雖然這個模型的預(yù)訓(xùn)練參數(shù)只有 893M,但卻需要在 512 塊 A100 上訓(xùn)練 10 天的時間。
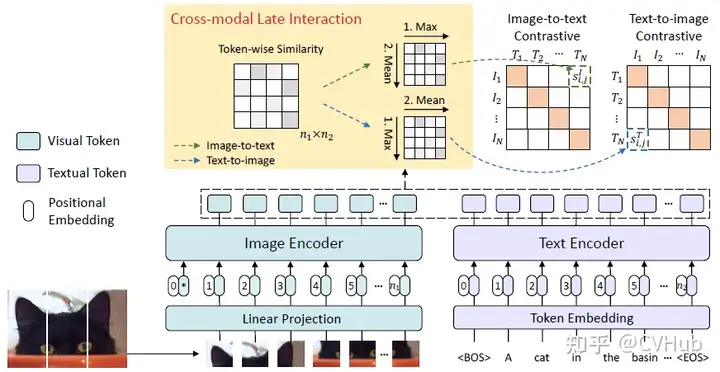
FILIP 提出了一種交叉模態(tài)的后期交互方法,以捕捉細(xì)粒度語義對齊。FILIP 損失最大化了視覺和文本嵌入之間逐標(biāo)記的相似性,有助于在不犧牲 CLIP 的推理效率的情況下,模擬兩種模態(tài)之間的細(xì)粒度交互。【作者在 VALSE 第59期分享過,有興趣的可以去看看,B站上有視頻】
此外還有基于掩碼對比學(xué)習(xí)的方法,這是一種通過遮擋輸入像素來提高對比學(xué)習(xí)效率的有效方法。下面我們也將介紹幾種典型方法。
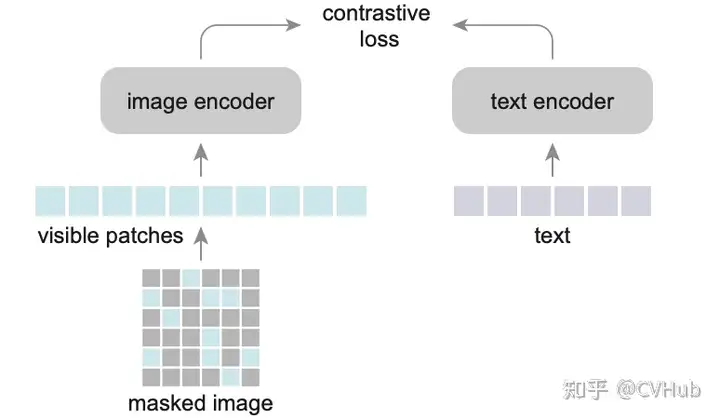
FLIP 是一種簡單和更有效的訓(xùn)練 CLIP 的方法,其思想很簡單,如圖所示,就是將 MAE 的 Mask 操作引入到 CLIP 上,隨機(jī)地 mask 掉具有高 mask 率的圖像碎片,只對可見的碎片進(jìn)行編碼。不同之處在于,這里不會對被 masked 的圖像內(nèi)容進(jìn)行重建。此外,對于文本也做同樣處理,有點(diǎn)類似于 BERT 但又不一樣,BERT 是用學(xué)習(xí)過的 mask token 來代替它們,這種稀疏的計算可以顯著減少文本編碼的成本。
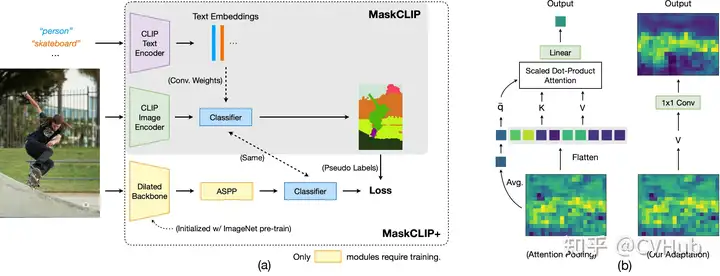
MaskCLIP 強(qiáng)調(diào)了圖像是一個連續(xù)且細(xì)粒度的信號,而語言描述可能無法完全表達(dá)這一點(diǎn)。因此,MaskCLIP 通過隨機(jī)遮擋圖像并利用基于 Mean Teacher 的自蒸餾來學(xué)習(xí)局部語義特征。
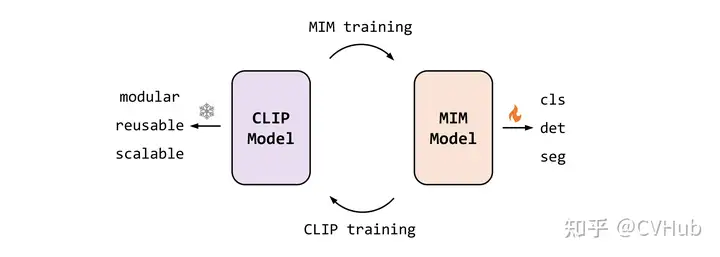
這是一個以視覺為中心的基礎(chǔ)模型,旨在僅使用可公開訪問的數(shù)據(jù)來探索大規(guī)模視覺表示的局限性。EVA 是由智源曹越團(tuán)隊最新開源的視覺預(yù)訓(xùn)練模型,通過將最強(qiáng)語義學(xué)習(xí)(CLIP)與最強(qiáng)幾何結(jié)構(gòu)學(xué)習(xí)(MIM)結(jié)合,僅需使用標(biāo)準(zhǔn)的 ViT 模型,并將其規(guī)模擴(kuò)大到十億參數(shù)(1-Billion)進(jìn)行訓(xùn)練,即可得到當(dāng)前最強(qiáng)大的十億級視覺基礎(chǔ)模型。
通過重構(gòu) CLIP 特征來進(jìn)行 MIM 操作。首先, CLIP 模型輸入為完整的圖像,而 EVA 模型的輸入為有遮擋的圖像,訓(xùn)練過程是讓 EVA 模型遮擋部分的輸出去重構(gòu) CLIP 模型對應(yīng)位置的輸出,從而以簡單高效的方式讓 EVA 模型同時擁有了最強(qiáng)語義學(xué)習(xí) CLIP 的能力和最強(qiáng)幾何結(jié)構(gòu)學(xué)習(xí) MIM 的能力。
很多的方法,總體而言,這些方法通過各種技術(shù),如調(diào)整架構(gòu),改進(jìn)對比目標(biāo),引入噪聲魯棒性,和探索多模態(tài)交互等,不斷推動了 CLIP 及其變種的發(fā)展。這些努力已經(jīng)展示了在許多任務(wù)上,包括零樣本分類和圖像-文本檢索任務(wù)等方面,如何改善模型的性能,從而使這些模型在計算機(jī)視覺和自然語言處理的交叉領(lǐng)域中變得越來越重要。
基于視覺定位基礎(chǔ)模型的方法

首先我們看下上圖展示的結(jié)果,可以觀察到,原始的 CLIP 模型其實(shí)是不擅長視覺定位任務(wù)的,特別是針對語義分割這種像素級定位任務(wù)來說。

RegionCLIP 顯著擴(kuò)展了 CLIP 以學(xué)習(xí)區(qū)域級視覺表示,其支持圖像區(qū)域和文本概念之間的細(xì)粒度對齊,從而支持基于區(qū)域的推理任務(wù),包括零樣本目標(biāo)檢測和開放詞匯目標(biāo)檢測。
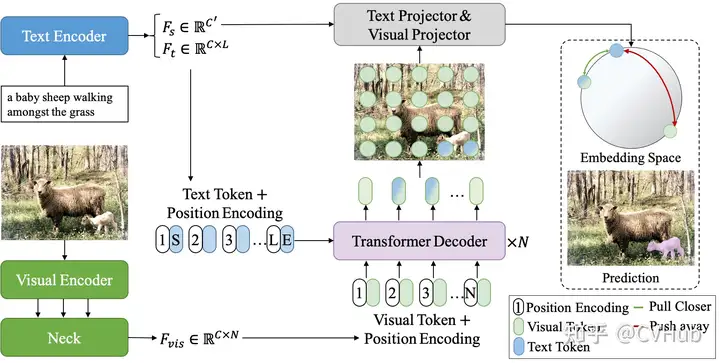
CRIS則通過引入視覺-語言解碼器和文本到像素對比損失,使 CLIP 框架學(xué)習(xí)像素級信息。
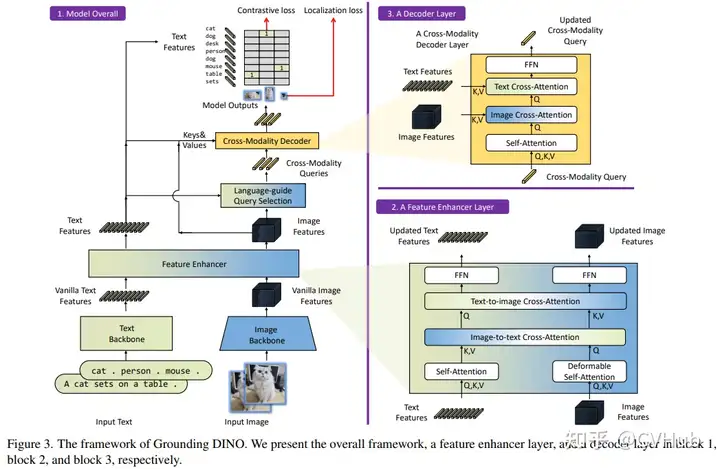
Grounding DINO 是由沈向洋領(lǐng)導(dǎo)的 IDEA 實(shí)驗(yàn)室開源的,該方案利用了強(qiáng)大的預(yù)訓(xùn)練模型,并通過對比學(xué)習(xí)進(jìn)行修改,以增強(qiáng)與語言的對齊。當(dāng)然,像 OWL-ViT 也是類似的工作。此外, IDEA 還基于 SAM 等基礎(chǔ)模型開源了一個集各大基礎(chǔ)模型的倉庫Grounded-Segment-Anything,倉庫幾乎涵蓋了市面上主流的視覺基礎(chǔ)模型,感興趣的也可以關(guān)注下:

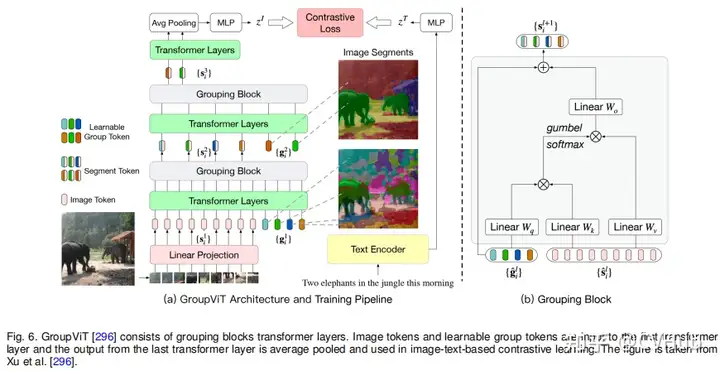
最后,我們一起看下 OpenSeg 和 GroupViT,這些方法著重于分組機(jī)制和分割效果,以通過對比學(xué)習(xí)實(shí)現(xiàn)更好的語義分割和目標(biāo)檢測。值得關(guān)注的是,MetaAI 近期也開放了一篇最新的工作 ZeroSeg,無需借助文本信息便可以輕松實(shí)現(xiàn)高質(zhì)量的分割效果,想要了解詳情的同學(xué)可關(guān)注公眾號 CVHub,搜索對應(yīng)關(guān)鍵詞即可。
簡單來說,以上討論涵蓋了一系列現(xiàn)代基礎(chǔ)模型研究,這些方法試圖通過對比學(xué)習(xí)、掩碼學(xué)習(xí)、擴(kuò)展和復(fù)現(xiàn)等技術(shù)來改進(jìn)CLIP和其它基礎(chǔ)模型。這些工作不僅推動了大規(guī)模圖像-文本建模的前沿,還為諸如目標(biāo)檢測、語義分割等特定視覺任務(wù)的解決方案提供了新的方法和框架。
基于生成式的方法
基于生成式方法的視覺基礎(chǔ)模型的總結(jié)涵蓋了多個領(lǐng)域和方向,下面筆者簡單歸納總結(jié)下。
首先是結(jié)合大語言模型(Large Language Model, LLM)的多模態(tài)學(xué)習(xí)范式:
結(jié)合上下文的多模態(tài)輸入學(xué)習(xí):例如
Frozen方法將圖像編碼器與LLM結(jié)合,無需更新LLM的權(quán)重,而是在帶有圖像標(biāo)注的數(shù)據(jù)集上訓(xùn)練視覺編碼器。類似地,Flamingo模型采用了固定的預(yù)訓(xùn)練視覺和語言模型,并通過Perceiver Resampler進(jìn)行連接。使用
LLM作為其它模態(tài)的通用接口:如MetaLM模型采用半因果結(jié)構(gòu),將雙向編碼器通過連接層連接到解碼器上,可實(shí)現(xiàn)多任務(wù)微調(diào)和指令調(diào)整零樣本學(xué)習(xí)。此外,KOSMOS系列也在LLM上整合了多模態(tài)學(xué)習(xí)的能力。開源版本的模型:如
OpenFlamingo,是Flamingo模型的開源版本,訓(xùn)練于新的多模態(tài)數(shù)據(jù)集。
其次我們來看下視覺-語言對齊與定位相關(guān)的模型:
具備定位能力的模型:
KOSMOS-2通過添加一條管線來抽取文本中的名詞短語并將其與圖像中的相應(yīng)區(qū)域鏈接起來,進(jìn)而實(shí)現(xiàn)視覺定位。
另外就是通用生成目標(biāo)下的訓(xùn)練:
簡化視覺語言建模:如
SimVLM使用前綴語言建模(PrefixLM)目標(biāo)進(jìn)行訓(xùn)練,不需要任務(wù)特定的架構(gòu)或訓(xùn)練,可在多個視覺語言任務(wù)上實(shí)現(xiàn)優(yōu)秀的性能。掩碼重構(gòu)與對齊:如
MaskVLM,采用聯(lián)合掩碼重構(gòu)語言建模,其中一個輸入的掩碼部分由另一個未掩碼輸入重構(gòu),有效對齊兩個模態(tài)。模塊化視覺語言模型:如
mPLUG-OWL,由圖像編碼器、圖像抽象器和凍結(jié)LLM組成,通過兩階段的訓(xùn)練實(shí)現(xiàn)多模態(tài)對話和理解。
此外還有與對比學(xué)習(xí)的比較與結(jié)合:
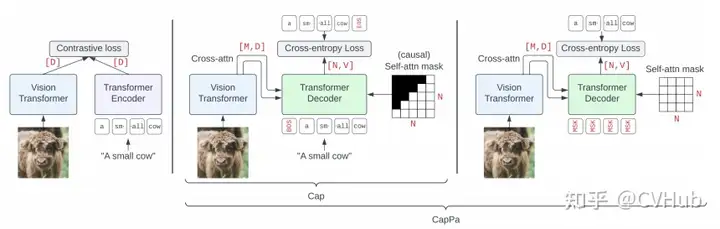
CapPa 是基于字幕的模型與 CLIP 風(fēng)格模型的比較得到的一種新的生成預(yù)訓(xùn)練方法,交替使用自回歸預(yù)測和并行預(yù)測。
總體而言,上述的方法和模型通過在視覺條件下訓(xùn)練語言生成任務(wù),為 LLM 增添了“看世界”的能力。這些工作在視覺語言任務(wù),如圖像標(biāo)注、多模態(tài)對話和理解等方面取得了顯著進(jìn)展,有的甚至在少樣本情況下達(dá)到或超越了最先進(jìn)的性能。通過將視覺和語言模態(tài)結(jié)合,這些模型為計算機(jī)視覺和自然語言處理的交叉領(lǐng)域提供了強(qiáng)大的新工具。
基于對比學(xué)習(xí)和生成式的混合方法
通用視覺-語言學(xué)習(xí)的基礎(chǔ)模型:
UNITER:結(jié)合了生成(例如掩碼語言建模和掩碼區(qū)域建模)和對比(例如圖像文本匹配和單詞區(qū)域?qū)R)目標(biāo)的方法,適用于異構(gòu)的視覺-語言任務(wù)。Pixel2Seqv2:將四個核心視覺任務(wù)統(tǒng)一為像素到序列的接口,使用編碼器-解碼器架構(gòu)進(jìn)行訓(xùn)練。Vision-Language:使用像 BART 或 T5 等預(yù)訓(xùn)練的編碼器-解碼器語言模型來學(xué)習(xí)不同的計算機(jī)視覺任務(wù)。
通用架構(gòu):
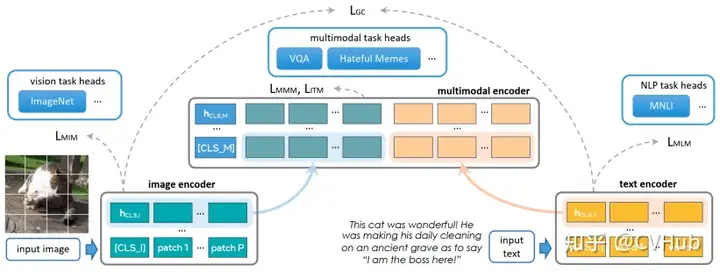
Contrastive Captioner (CoCa):結(jié)合了對比損失和生成式的字幕損失,可以在多樣的視覺數(shù)據(jù)集上表現(xiàn)良好。FLAVA:適用于單模態(tài)和多模態(tài)任務(wù),通過一系列損失函數(shù)進(jìn)行訓(xùn)練,以便在視覺、語言和視覺-語言任務(wù)上表現(xiàn)良好。BridgeTower:結(jié)合了不同層次的單模態(tài)解碼器的信息,不影響執(zhí)行單模態(tài)任務(wù)的能力。PaLI:一種共同擴(kuò)展的多語言模塊化語言-視覺模型,適用于單模態(tài)和多模態(tài)任務(wù)。X-FM:包括語言、視覺和融合編碼器的新基礎(chǔ)模型,通過組合目標(biāo)和新技術(shù)進(jìn)行訓(xùn)練。
BLIP 框架范式:
BLIP:利用生成和理解能力有效利用圖像文本數(shù)據(jù)集,采用Multimodal mixture of Encoder-Decoder (MED)架構(gòu)。BLIP-2:通過查詢轉(zhuǎn)換器來實(shí)現(xiàn)計算效率高的模態(tài)間對齊。
指令感知特征提取和多模態(tài)任務(wù)解決方案:
InstructBLIP:利用視覺編碼器、Q-Former和LLM,通過指令感知的視覺特征提取來進(jìn)行訓(xùn)練。 對預(yù)訓(xùn)練模型的高效利用:VPGTrans:提供了一種高效的方法來跨 LLM 傳輸視覺編碼器。TaCA:提到了一種叫做TaCA的適配器,但沒有進(jìn)一步詳細(xì)描述。
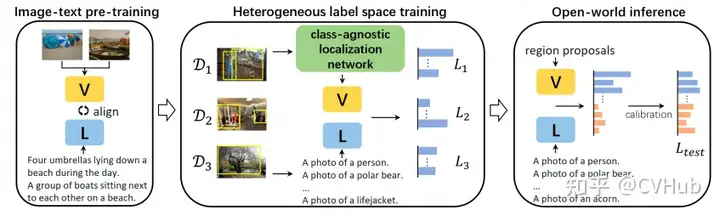
基于 Visual Grounding 的方法:
ViLD: 這一方法使用了一個兩階段的開放詞匯對象檢測系統(tǒng),從預(yù)訓(xùn)練的單詞匯分類模型中提取知識。它包括一個RPN和一個類似于CLIP的視覺語言模型,使用Mask-RCNN創(chuàng)建對象提案,然后將知識提取到對象檢測器中。UniDetector: 此方法旨在進(jìn)行通用對象檢測,以在開放世界中檢測新的類別。它采用了三階段訓(xùn)練方法,包括類似于上面我們提到的RegionCLIP的預(yù)訓(xùn)練、異構(gòu)數(shù)據(jù)集訓(xùn)練以及用于新類別檢測的概率校準(zhǔn)。UniDetector 為大詞匯和封閉詞匯對象檢測設(shè)立了新的標(biāo)準(zhǔn)。X-Decoder: 在三個粒度層次(圖像級別、對象級別和像素級別)上運(yùn)作,以利用任務(wù)協(xié)同作用。它基于Mask2Former,采用多尺度圖像特征和兩組查詢來解碼分割掩碼,從而促進(jìn)各種任務(wù)。它在廣泛的分割和視覺語言任務(wù)中展現(xiàn)出強(qiáng)大的可轉(zhuǎn)移性。
這些方法共同探討了視覺定位任務(wù)的不同維度,包括開放詞匯對象檢測、通用對象檢測、兩階段訓(xùn)練、多級粒度和新穎的損失功能。它們共同通過以創(chuàng)新的方式整合視覺和語言來推動視覺理解的界限,往往超越了該領(lǐng)域以前的基準(zhǔn)。
簡單總結(jié)下,上面我們展示了如何通過對比和生成式學(xué)習(xí),以及混合這些方法,來設(shè)計和訓(xùn)練可以處理各種視覺和語言任務(wù)的模型。有些模型主要關(guān)注提高單模態(tài)和多模態(tài)任務(wù)的性能,而有些模型關(guān)注如何高效地訓(xùn)練和利用預(yù)訓(xùn)練模型。總的來說,這些研究提供了視覺-語言融合研究的豐富視角和多樣化方法,以滿足不同的實(shí)際需求和應(yīng)用場景。
基于對話式的視覺語言模型
這一塊我們不做過多介紹,僅介紹比較有代表性的幾個工作:

GPT-4:這是首個結(jié)合視覺和語言的模型,能夠進(jìn)行多模態(tài)對話。該模型基于Transformer架構(gòu),通過使用公開和私有數(shù)據(jù)集進(jìn)行預(yù)訓(xùn)練,并通過人類反饋進(jìn)行強(qiáng)化學(xué)習(xí)微調(diào)。根據(jù)公開的數(shù)據(jù),GPT-4 在多個 NLP、視覺和視覺-語言任務(wù)上表現(xiàn)出色,但很可惜目前并未開源。
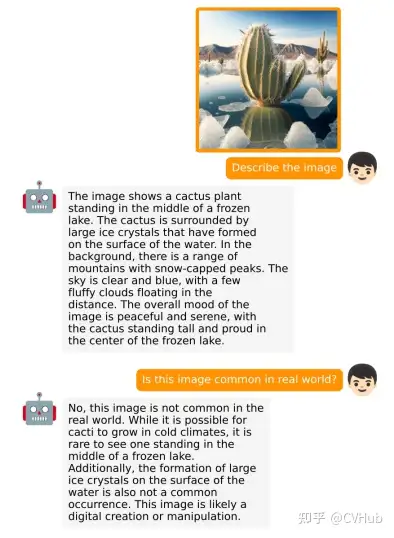
miniGPT-4: 作為GPT-4的開源版本,miniGPT-4 由預(yù)訓(xùn)練的大型語言模型Vicuna和視覺組件ViT-G和Q-Former組成。模型先在多模態(tài)示例上進(jìn)行訓(xùn)練,然后在高質(zhì)量的圖像和文本對上進(jìn)行微調(diào)。miniGPT-4 能夠生成復(fù)雜的圖像描述并解釋視覺場景。
XrayGPT: 這個模型可以分析和回答有關(guān) X 射線放射圖的開放式問題。使用Vicuna LLM作為文本編碼器和MedClip作為圖像編碼器,通過更新單個線性投影層來進(jìn)行多模態(tài)對齊。
LLaVA: 這是一個開源的視覺指令調(diào)整框架和模型,由兩個主要貢獻(xiàn)組成:開發(fā)一種用于整理多模態(tài)指令跟蹤數(shù)據(jù)的經(jīng)濟(jì)方法,以及開發(fā)一個大型多模態(tài)模型,該模型結(jié)合了預(yù)訓(xùn)練的語言模型LLaMA和CLIP的視覺編碼器。
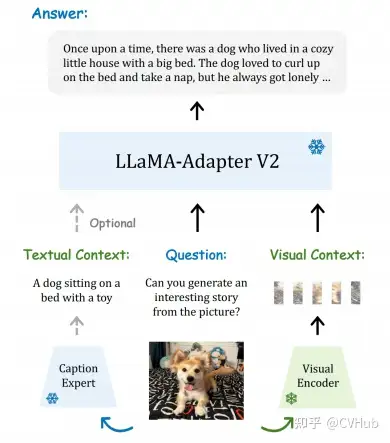
LLaMA-Adapter V2: 通過引入視覺專家,早期融合視覺知識,增加可學(xué)習(xí)參數(shù)等方式,改善了LLaMA的指令跟隨能力,提高了在傳統(tǒng)視覺-語言任務(wù)上的性能。
綜上所述,基于對話的視覺語言模型在理解、推理和進(jìn)行人類對話方面取得了顯著進(jìn)展。通過將視覺和語言結(jié)合在一起,這些模型不僅在傳統(tǒng) NLP 任務(wù)上表現(xiàn)出色,而且能夠解釋復(fù)雜的視覺場景,甚至能夠與人類進(jìn)行復(fù)雜的多模態(tài)對話。未來可能會有更多的工作致力于提高這些模型的可解釋性、可用性和可訪問性,以便在更廣泛的應(yīng)用領(lǐng)域中實(shí)現(xiàn)其潛力。
需要完整 PDF 版本請?zhí)砑游⑿盘? cv_huber,備注“視覺大模型”即可領(lǐng)取!
基于視覺提示的基礎(chǔ)模型
這一塊內(nèi)容我們先為大家闡述幾個代表性的基于視覺提示的基礎(chǔ)模型,如 SAM 和 SEEM 等;隨后再介紹基于 SAM 的一系列改進(jìn)和應(yīng)用,例如用在醫(yī)療、遙感、視頻追蹤等領(lǐng)域;最后再簡單介紹下幾個通用的擴(kuò)展。
視覺基礎(chǔ)模型
CLIPSeg
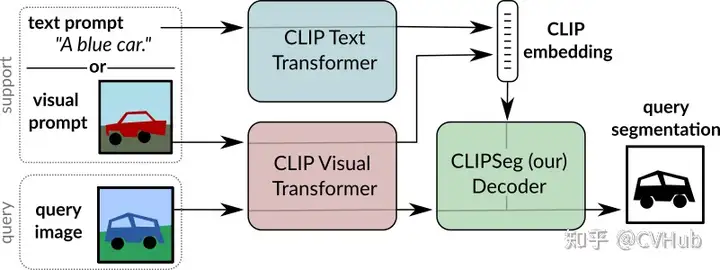
概述:CLIPSeg 利用 CLIP 的泛化能力執(zhí)行
zero-shot和one-shot分割任務(wù)。結(jié)構(gòu):由基于 CLIP 的圖像和文本編碼器以及具有 U-net 式跳躍連接的基于
Transformer的解碼器組成。工作方式:視覺和文本查詢通過相應(yīng)的 CLIP 編碼器獲取嵌入,然后饋送到 CLIPSeg 解碼器。因此,CLIPSeg 可以基于任意提示在測試時生成圖像分割。
SegGPT
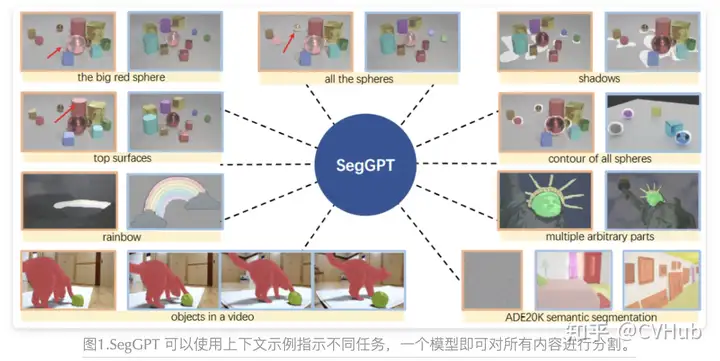
SegGPT 旨在訓(xùn)練一個通用模型,可以用于解決所有的分割任務(wù),其訓(xùn)練被制定為一個上下文著色問題,為每個數(shù)據(jù)樣本隨機(jī)分配顏色映射。目標(biāo)是根據(jù)上下文完成不同的分割任務(wù),而不是依賴于特定的顏色。
SAM
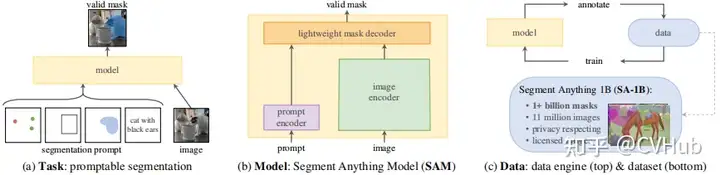
概述:SAM 是一種零樣本分割模型,從頭開始訓(xùn)練,不依賴于 CLIP。 結(jié)構(gòu):使用圖像和提示編碼器對圖像和視覺提示進(jìn)行編碼,然后在輕量級掩碼解碼器中組合以預(yù)測分割掩碼。 訓(xùn)練方法:通過三階段的數(shù)據(jù)注釋過程(輔助手動、半自動和全自動)訓(xùn)練。
SEEM
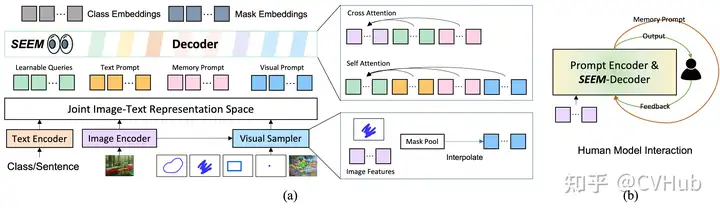
與 SAM 相比,SEEM 涵蓋了更廣泛的交互和語義層面。例如,SAM 只支持有限的交互類型,如點(diǎn)和框,而由于它本身不輸出語義標(biāo)簽,因此錯過了高語義任務(wù)。
首先,SEEM 有一個統(tǒng)一的提示編碼器,將所有視覺和語言提示編碼到聯(lián)合表示空間中。因此,SEEM 可以支持更通用的用途。它有潛力擴(kuò)展到自定義提示。其次,SEEM 在文本掩碼(基礎(chǔ)分割)方面非常有效,并輸出語義感知預(yù)測。
SAM 的改進(jìn)與應(yīng)用
SAM for Medical Segmentation

Adapting by Fine-Tuning
MedSAM:通過在大規(guī)模醫(yī)學(xué)分割數(shù)據(jù)集上微調(diào) SAM,創(chuàng)建了一個用于通用醫(yī)學(xué)圖像分割的擴(kuò)展方法 MedSAM。這一方法在 21 個 3D 分割任務(wù)和 9 個 2D 分割任務(wù)上優(yōu)于 SAM。
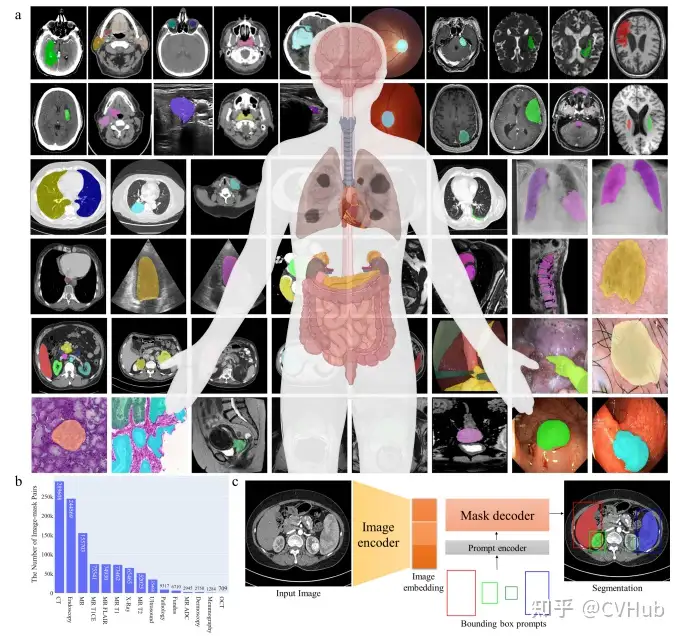
paper: https://arxiv.org/pdf/2304.12306.pdf
github: https://github.com/bowang-lab/MedSAM
Adapting through Auxiliary Prompt Encoder
AutoSAM:為SAM的提示生成了一個完全自動化的解決方案,基于輸入圖像由AutoSAM輔助提示編碼器網(wǎng)絡(luò)生成替代提示。AutoSAM 與原始的 SAM 相比具有更少的可訓(xùn)練參數(shù)。
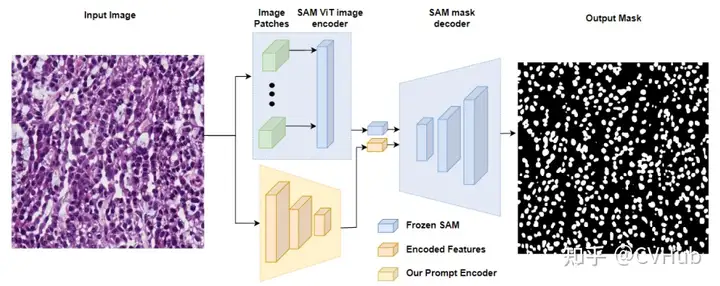
Adapting Through Adapters
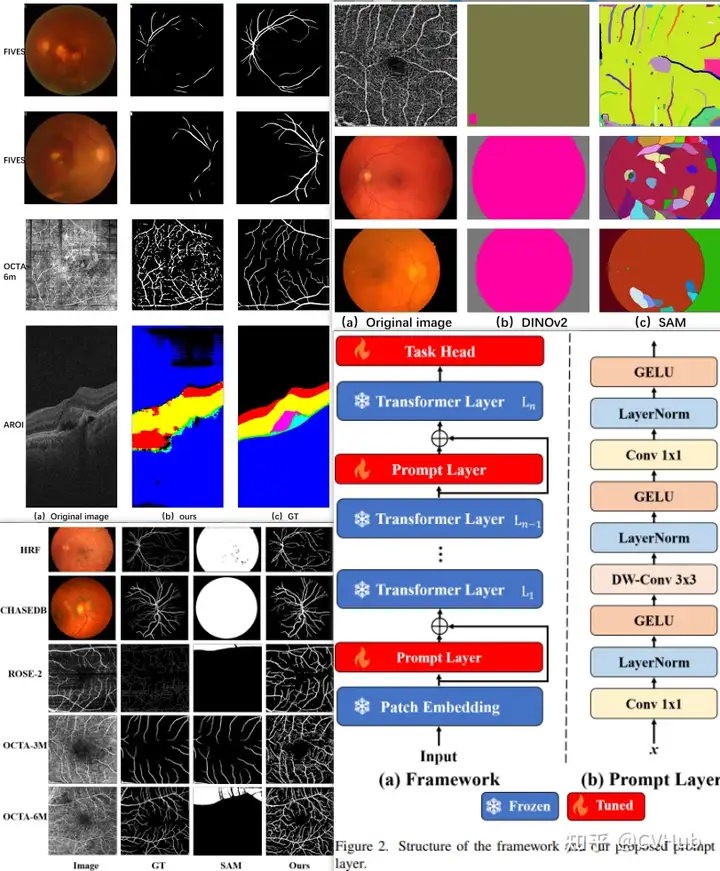
在眼科的多目標(biāo)分割:通過學(xué)習(xí)新的可學(xué)習(xí)的提示層對SAM進(jìn)行了一次微調(diào),從而準(zhǔn)確地分割不同的模態(tài)圖像中的血管或病變或視網(wǎng)膜層。
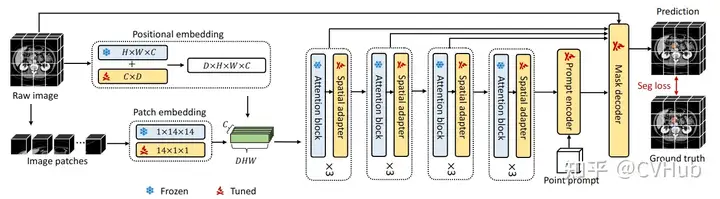
3DSAM-adapter:為了適應(yīng)3D空間信息,提出了一種修改圖像編碼器的方案,使原始的2D變換器能夠適應(yīng)體積輸入。
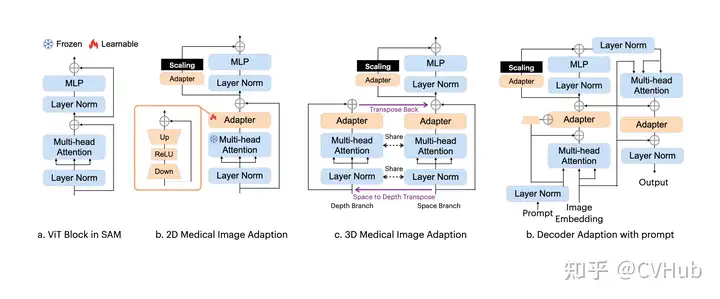
Medical SAM Adapter:專為SAM設(shè)計了一個通用的醫(yī)學(xué)圖像分割適配器,能夠適應(yīng)醫(yī)學(xué)數(shù)據(jù)的高維度(3D)以及獨(dú)特的視覺提示,如 point 和 box。
Adapting by Modifying SAM’s Decoder
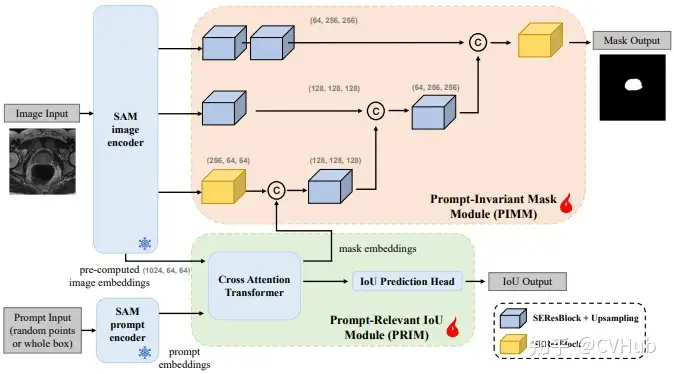
DeSAM:提出了將 SAM 的掩碼解碼器分成兩個子任務(wù):提示相關(guān)的 IoU 回歸和提示不變的掩碼學(xué)習(xí)。DeSAM 最小化了錯誤提示在“分割一切”模式下對SAM性能的降低。
SAM as a Medical Annotator
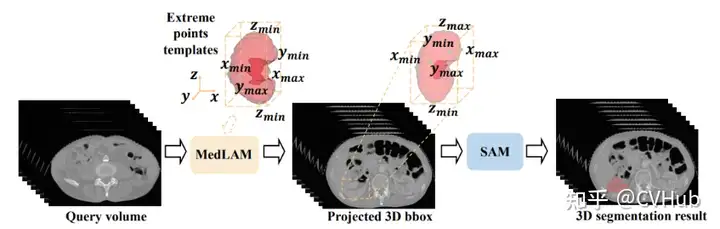
MedLAM:提出了一個使用 SAM 的醫(yī)學(xué)數(shù)據(jù)集注釋過程,并引入了一個少量定位框架。MedLAM 顯著減少了注釋負(fù)擔(dān),自動識別整個待注釋數(shù)據(jù)集的目標(biāo)解剖區(qū)域。
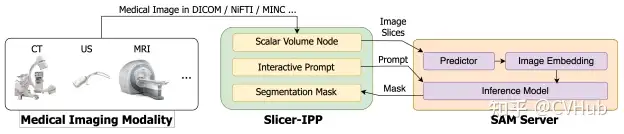
Segment Any Medical Model, SAMM:這是一個結(jié)合了3D Slicer和SAM的醫(yī)學(xué)圖像分割工具,協(xié)助開發(fā)、評估和應(yīng)用SAM。通過與3D Slicer的整合,研究人員可以使用先進(jìn)的基礎(chǔ)模型來分割醫(yī)學(xué)圖像。
總體來說,通過各種微調(diào)、適配和修改方法,SAM 已被成功適應(yīng)了用于醫(yī)學(xué)圖像分割的任務(wù),涵蓋了從器官、病變到組織的不同醫(yī)學(xué)圖像。這些方法也突出了將自然圖像的深度學(xué)習(xí)技術(shù)遷移到醫(yī)學(xué)領(lǐng)域的潛力和挑戰(zhàn)。在未來,SAM 及其變體可能會繼續(xù)推動醫(yī)學(xué)圖像分析領(lǐng)域的進(jìn)展。
SAM for Tracking
SAM 在跟蹤任務(wù)方面的應(yīng)用集中在通過視頻中的幀跟蹤和分割任意對象,通常被稱為視頻對象分割(VOS)。這個任務(wù)涉及在一般場景中識別和追蹤感興趣的區(qū)域。以下總結(jié)下 SAM 在跟蹤方面的一些主要應(yīng)用和方法:
Track Anything (TAM)
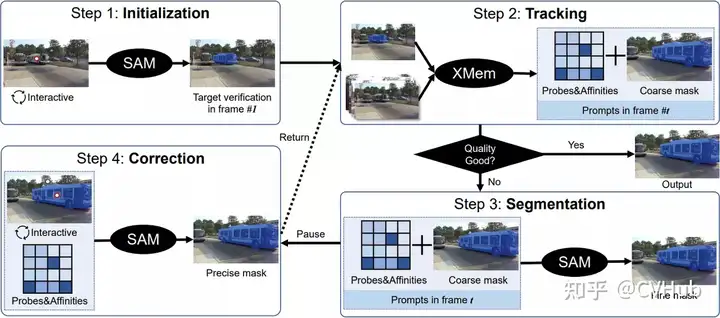
概述:TAM 使用 SAM 和現(xiàn)成的跟蹤器 XMem 來分割和跟蹤視頻中的任何對象。 操作方式:用戶可以簡單地點(diǎn)擊一個對象以初始化 SAM 并預(yù)測掩碼。然后,XMem 使用 SAM提供的初始掩碼預(yù)測在視頻中基于時空對應(yīng)關(guān)系跟蹤對象。用戶可以暫停跟蹤過程并立即糾正任何錯誤。 挑戰(zhàn):雖然表現(xiàn)良好,但 TAM 在零樣本場景下不能有效保留 SAM 的原始性能。
SAM-Track
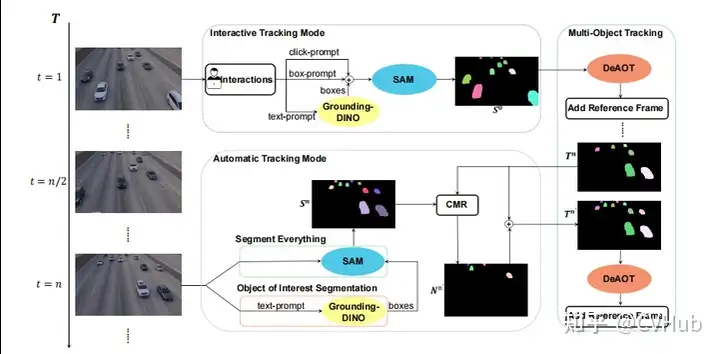
概述:與 TAM 類似,SAM-Track 使用 DeAOT 與 SAM 結(jié)合。 挑戰(zhàn):與 TAM 類似,SAM-Track 在零樣本場景下也存在性能挑戰(zhàn)。
SAM-PT
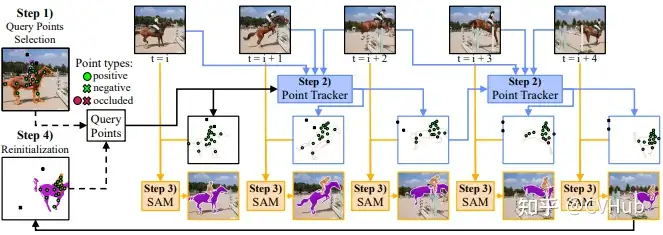
概述:SAM-PT 通過結(jié)合 SAM 的稀疏點(diǎn)跟蹤來解決視頻分割問題。只需要第一幀的稀疏點(diǎn)注釋來表示目標(biāo)對象。 強(qiáng)項:在開放世界 UVO 基準(zhǔn)測試中展示了對未見對象的泛化能力。 操作方式:使用像 PIPS 這樣的先進(jìn)點(diǎn)跟蹤器,SAM-PT 為視頻分割提供稀疏點(diǎn)軌跡預(yù)測。進(jìn)一步地,為了區(qū)分目標(biāo)對象及其背景,SAM-PT 同時跟蹤正點(diǎn)和負(fù)點(diǎn)。
SAM-DA
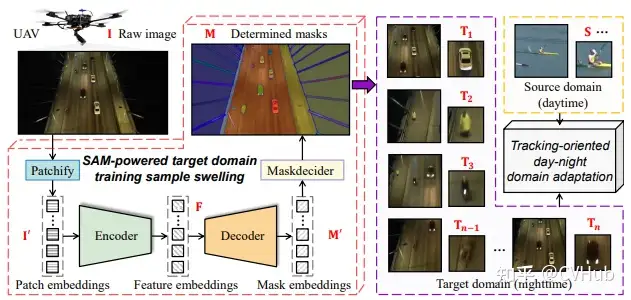
概述:SAM-DA 是另一種使用 SAM 自動分割能力進(jìn)行跟蹤的方法。 具體應(yīng)用:通過使用 SAM 自動分割功能從每個夜間圖像自動確定大量高質(zhì)量目標(biāo)域訓(xùn)練樣本,從而跟蹤夜間無人機(jī)(UAVs)。
SAM 在視頻對象跟蹤和分割方面的應(yīng)用表明了其作為分割基礎(chǔ)模型的潛力。盡管有一些挑戰(zhàn),特別是在未見數(shù)據(jù)和零樣本場景下,但通過與現(xiàn)成的跟蹤器的結(jié)合以及稀疏點(diǎn)跟蹤的使用,SAM 能夠?qū)崿F(xiàn)在視頻中跟蹤和分割對象。這些方法為計算機(jī)視覺社區(qū)提供了一個實(shí)現(xiàn)通用場景中任意對象跟蹤的有力工具,有助于推動視頻分析和監(jiān)控等領(lǐng)域的進(jìn)展。
SAM for Remote Sensing
SAM 在遙感圖像分割方面的應(yīng)用集中在通過點(diǎn)、框和粗粒度掩碼的引導(dǎo)來理解和分割遙感圖像。以下是 SAM 在遙感分割方面的應(yīng)用以及相關(guān)挑戰(zhàn)。
SAM在遙感分割的基本應(yīng)用
交互性質(zhì):由于 SAM 的交互特性,它主要依賴于點(diǎn)、框和粗粒度掩碼的手動引導(dǎo)。
限制:
全自動分割困難:SAM在完全自動地理解遙感圖像方面效果不佳。
結(jié)果依賴性:SAM的結(jié)果嚴(yán)重依賴于用于分割遙感圖像目標(biāo)的提示的類型、位置和數(shù)量。
手動提示優(yōu)化需求:要實(shí)現(xiàn)理想的結(jié)果,通常需要對手動提示進(jìn)行精煉。
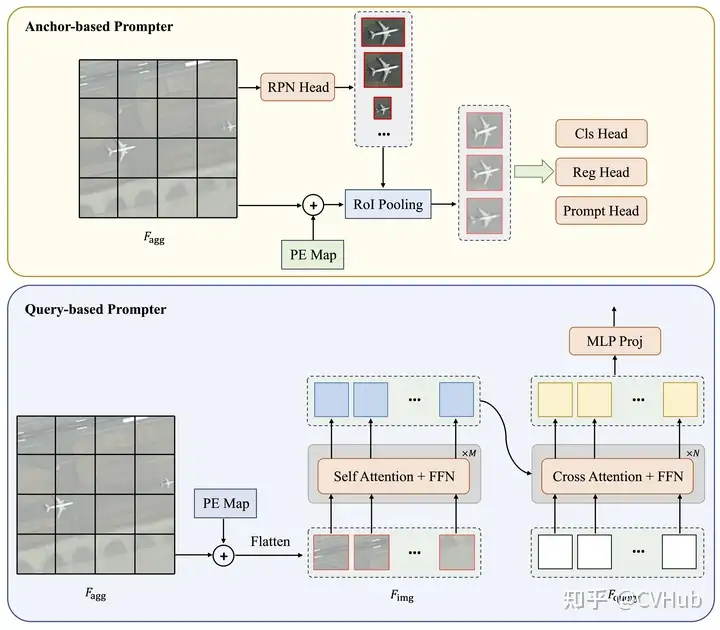
概述:RsPrompter 是一個將語義分類信息與 SAM 結(jié)合的方法,用于遙感圖像的自動實(shí)例分割。 操作方式:
學(xué)習(xí)生成提示:RsPrompter 提出了一種學(xué)習(xí)生成適當(dāng)?shù)腟AM輸入提示的方法。 生成提示包含的信息:通過分析編碼器的中間層來生成包含關(guān)于語義類別的信息的提示,并生成提示嵌入,這可以視為點(diǎn)或框嵌入。 目標(biāo):通過自動化生成適當(dāng)?shù)妮斎胩崾荆琑sPrompter 試圖克服 SAM 在遙感圖像分割方面的局限性。
盡管 SAM 在遙感圖像分割方面存在一些限制,主要與其交互性質(zhì)和對手動引導(dǎo)的依賴有關(guān),但通過引入如 RsPrompter 這樣的方法,可以利用 SAM 實(shí)現(xiàn)遙感圖像的自動實(shí)例分割。這些努力標(biāo)志著朝著減少人工干預(yù)和提高遙感圖像分析自動化的方向邁出的重要一步,有勢必推動遙感科學(xué)、地理信息系統(tǒng)(GIS)和環(huán)境監(jiān)測等領(lǐng)域的進(jìn)展。
SAM for Captioning
SAM 與大型語言模型如 ChatGPT 的組合在可控圖像字幕(controlled image captioning)方面開辟了新的應(yīng)用領(lǐng)域。下面概述下這種組合在圖像字幕上的具體應(yīng)用。
先給大家介紹下概念,可控圖像字幕使用自然語言來根據(jù)人類目標(biāo)解釋圖像,例如檢查圖像的某些區(qū)域或以特定方式描述圖像。然而,這種交互式圖像字幕系統(tǒng)的可擴(kuò)展性和可用性受到缺乏良好注釋的多模態(tài)數(shù)據(jù)的限制。一個典型的案例便是 Caption AnyThing,下面一起看看。

概述:Caption AnyThing 是一種零樣本圖像字幕模型,通過與 SAM 和大型語言模型(例如ChatGPT)結(jié)合,使用預(yù)訓(xùn)練的圖像字幕器實(shí)現(xiàn)。
工作流程:
定義視覺控制:用戶可以通過視覺提示定義視覺控制。
使用SAM轉(zhuǎn)換為掩碼:視覺提示隨后使用SAM轉(zhuǎn)換為掩碼,以選擇感興趣的區(qū)域。
預(yù)測原始字幕:基于原始圖像和提供的掩碼,圖像字幕器預(yù)測原始字幕。
文本優(yōu)化:使用大型語言模型(例如ChatGPT)的文本精煉器,根據(jù)用戶的偏好定制語言風(fēng)格,從而優(yōu)化原始描述。
結(jié)果:用戶可以通過控制視覺和語言方面,更精確地描述圖像中的特定部分或?qū)傩浴?/p>
優(yōu)勢和意義
用戶自定義:通過允許用戶定義視覺和語言控制,提供了高度定制的解釋。
靈活性和準(zhǔn)確性:通過結(jié)合視覺分割和自然語言處理,增強(qiáng)了描述的靈活性和準(zhǔn)確性。
零樣本學(xué)習(xí):由于是零樣本模型,因此可以在未經(jīng)特定訓(xùn)練的新圖像和場景上工作。
通過結(jié)合 SAM 的圖像分割能力和大型語言模型如 ChatGPT 的自然語言處理能力,Caption AnyThing 為可控圖像字幕開辟了新的可能性。這不僅增強(qiáng)了字幕的靈活性和準(zhǔn)確性,還允許用戶定制語言風(fēng)格和焦點(diǎn),從而促進(jìn)了交互圖像分析和解釋的發(fā)展
SAM for Mobile Applications
這一節(jié)我們重點(diǎn)梳理下 SAM 的一些移動端應(yīng)用,主要就是加速 SAM 的推理和提升 SAM 的分割質(zhì)量。
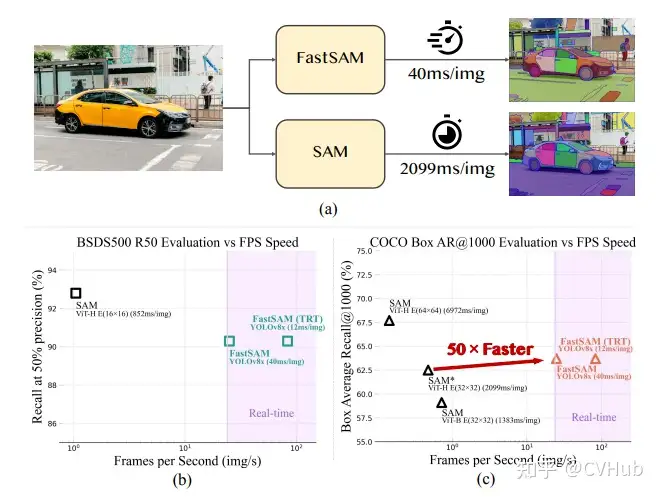
FastSAM 基于 YOLOv8-seg 實(shí)現(xiàn),它比 SAM 快50倍,且訓(xùn)練數(shù)據(jù)只有SAM的1/50,同時運(yùn)行速度不受 point 輸入數(shù)量的影響
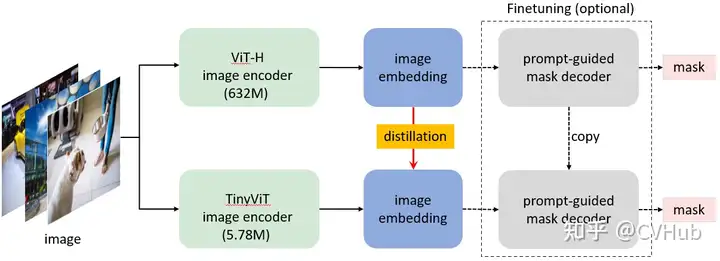
MobileSAM:將原始 SAM 中的圖像編碼器 ViT-H 的知識蒸餾到一個輕量化的圖像編碼器中,該編碼器可以自動與原始 SAM 中的 Mask 解碼器兼容。訓(xùn)練可以在不到一天的時間內(nèi)在單個 GPU 上完成,它比原始 SAM 小60多倍,但性能與原始 SAM 相當(dāng)。
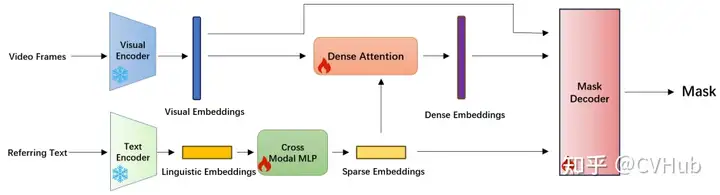
RefSAM:這是一種高效的端到端基于 SAM 的框架,用于指代視頻對象分割(RVOS)。它使用了高效且輕量級的CrossModal MLP,將指代表達(dá)的文本特征轉(zhuǎn)換為密集和稀疏的特征表示。
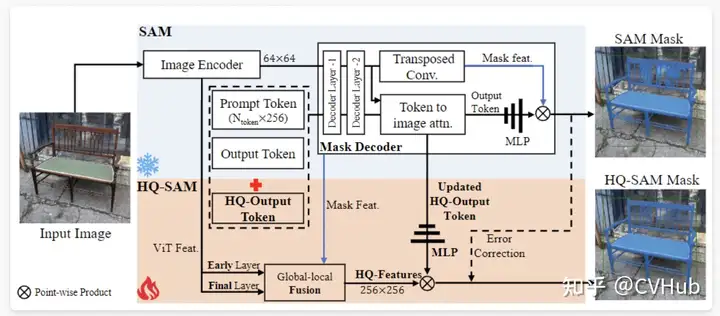
HQ-SAM: HQ-SAM 為了實(shí)現(xiàn)高質(zhì)量的掩膜預(yù)測,將 HQ-Output Token(高質(zhì)量輸出標(biāo)記)和全局-局部特征融合引入到SAM中。為了保持SAM的零樣本能力,輕量級的 HQ-Output Token 復(fù)用了 SAM 的掩膜解碼器,并生成了新的 MLP(多層感知器)層來執(zhí)行與融合后的 HQ-Features(高質(zhì)量特征)的逐點(diǎn)乘積。在訓(xùn)練期間,將預(yù)訓(xùn)練的 SAM 的模型參數(shù)固定,只有 HQ-SAM 中的少數(shù)可學(xué)習(xí)參數(shù)可以進(jìn)行訓(xùn)練。
通才模型
這一類主要描述如何使用上下文學(xué)習(xí)快速適應(yīng)具有不同提示和示例的各種任務(wù)。這里特別突出了幾個被稱為通才模型(Generalist Models)的模型,它們可以執(zhí)行多個任務(wù),甚至可以通過提示和少量特定于任務(wù)的示例來適應(yīng)新任務(wù)。
Painter
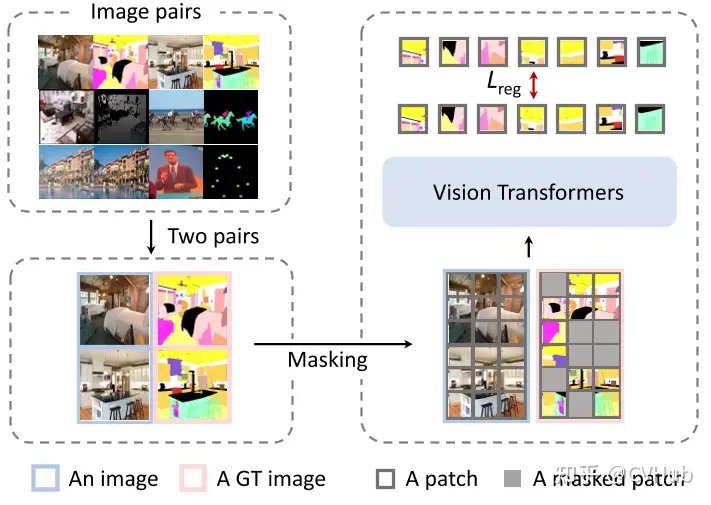
Painter是一種通才模型,可以同時執(zhí)行不同的任務(wù),甚至可以根據(jù)提示和非常少的特定于任務(wù)的示例適應(yīng)新任務(wù)。
工作方式:給定某個任務(wù)的輸入和輸出圖像,輸出圖像的像素被遮擋。Painter 模型的目標(biāo)是對 masked 的輸出圖像進(jìn)行填充。 訓(xùn)練目標(biāo):這個簡單的訓(xùn)練目標(biāo)允許統(tǒng)一幾個視覺任務(wù),包括深度估計、人體關(guān)鍵點(diǎn)檢測、語義分割、實(shí)例分割、圖像去噪、圖像去雨和圖像增強(qiáng)。 推理流程:在訓(xùn)練后,Painter 可以使用與輸入條件相同任務(wù)的輸入/輸出配對圖像來確定在推理過程中執(zhí)行哪個任務(wù)。
VisionLLM
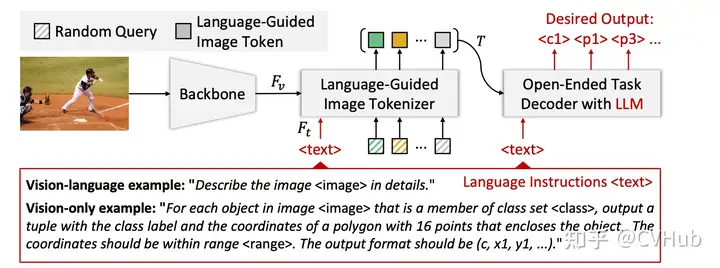
VisionLLM是另一個通才模型,可以對齊視覺和語言模態(tài)以解決開放式任務(wù)。
工作方式:給定圖像,VisionLLM 使用視覺模型學(xué)習(xí)圖像特征;這些圖像特征與例如“詳細(xì)描述圖像”的語言指令一起傳遞給語言引導(dǎo)的圖像分詞器。 任務(wù)解碼器:圖像分詞器的輸出連同語言指令被提供給一個開放式 LLM 為基礎(chǔ)的任務(wù)解碼器,旨在根據(jù)語言指令協(xié)調(diào)各種任務(wù)。
Prismer
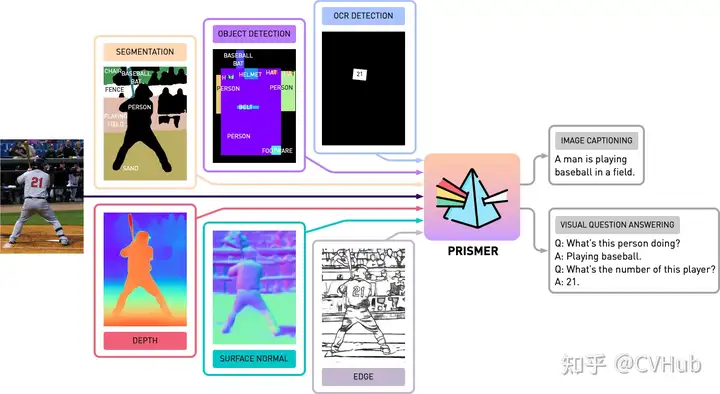
Prismer也是一種視覺語言模型,可以執(zhí)行多個推理任務(wù)。
特點(diǎn):Prismer 利用各種預(yù)訓(xùn)練的領(lǐng)域?qū)<遥缯Z義分割、對象、文本和邊緣檢測,表面法線和深度估計,來執(zhí)行多個推理任務(wù)。 應(yīng)用:例如圖像字幕和視覺問題回答。
通才模型表示了一種通用的趨勢,其中模型可以通過改變輸入或少量特定于任務(wù)的訓(xùn)練來適應(yīng)新的或多樣化的任務(wù)。這些模型在解決問題時可以靈活地適應(yīng),克服了單一任務(wù)模型的限制。尤其是在輸出表示在任務(wù)之間有很大差異的計算機(jī)視覺中,這一點(diǎn)變得尤為重要。通過簡化訓(xùn)練目標(biāo)和建立跨任務(wù)的框架,這些通才模型為未來計算機(jī)視覺任務(wù)的多功能性提供了新的機(jī)會。
需要完整 PDF 版本請?zhí)砑游⑿盘? cv_huber,備注“視覺大模型”即可領(lǐng)取!
綜合性基礎(chǔ)模型
基于異構(gòu)架構(gòu)的基礎(chǔ)視覺模型
在這一部分,我們集中討論不同的基礎(chǔ)視覺模型,這些模型通過對齊多個成對的模態(tài),如圖像-文本、視頻-音頻或圖像-深度等,來學(xué)習(xí)更有意義的表示。
CLIP 與異構(gòu)模態(tài)的對齊
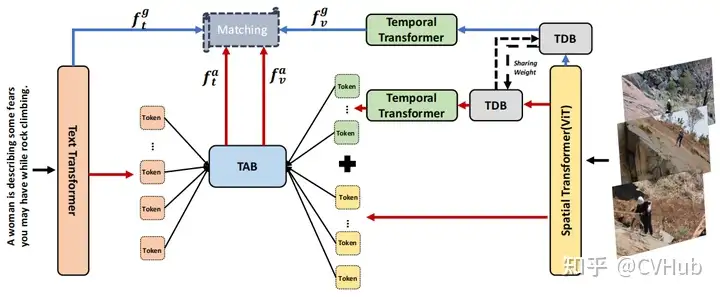
CLIP2Video:這一模型擴(kuò)展了CLIP模型,使其適用于視頻。通過引入時序一致性和提出的時序差異塊(TDB)和時序?qū)R塊(TAB),將圖像-文本的CLIP模型的空間語義轉(zhuǎn)移到視頻-文本檢索問題中。
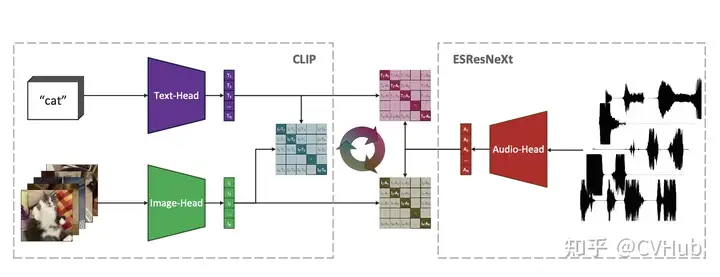
AudioCLIP:這一模型擴(kuò)展了CLIP,使其能夠處理音頻。AudioCLIP結(jié)合了ESResNeXt音頻模型,并在訓(xùn)練后能夠同時處理三種模態(tài),并在環(huán)境聲音分類任務(wù)中勝過先前方法。
學(xué)習(xí)共享表示的多模態(tài)模型
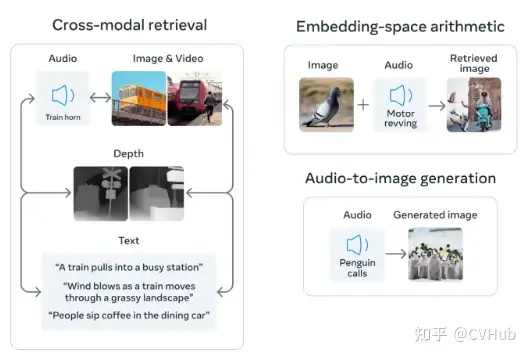
Image Bind:這一模型通過學(xué)習(xí)配對數(shù)據(jù)模態(tài)(如(視頻,音頻)或(圖像,深度))的共同表示,包括多種模態(tài)。ImageBind 將大規(guī)模配對數(shù)據(jù)(圖像,文本)與其他配對數(shù)據(jù)模態(tài)相結(jié)合,從而跨音頻、深度、熱和慣性測量單元(IMU)等四種模態(tài)擴(kuò)展零樣本能力。
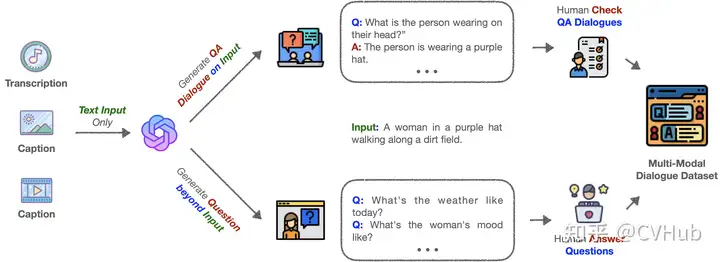
MACAW-LLM:這是一種指令調(diào)諧的多模態(tài) LLM(大型語言模型),整合了圖像、視頻、音頻和文本等四種不同模態(tài)。通過模態(tài)模塊、對齊模塊和認(rèn)知模塊,MACAW-LLM 實(shí)現(xiàn)了各種模態(tài)的統(tǒng)一。
視頻和長篇幅文本的處理
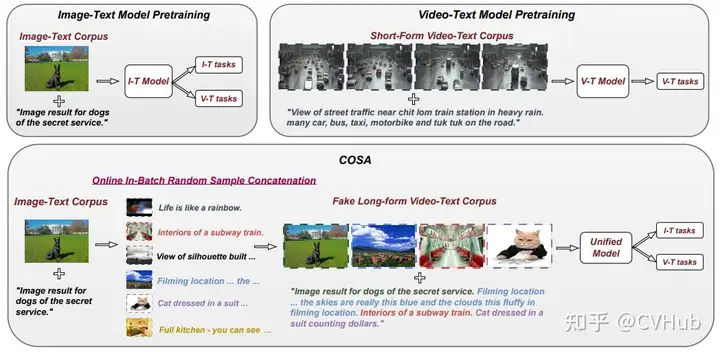
COSA:通過將圖像-文本語料庫動態(tài)轉(zhuǎn)換為長篇幅視頻段落樣本來解決視頻所需的時序上下文缺失問題。通過隨機(jī)串聯(lián)圖像-文本訓(xùn)練樣本,確保事件和句子的顯式對應(yīng),從而創(chuàng)造了豐富的場景轉(zhuǎn)換和減少視覺冗余。
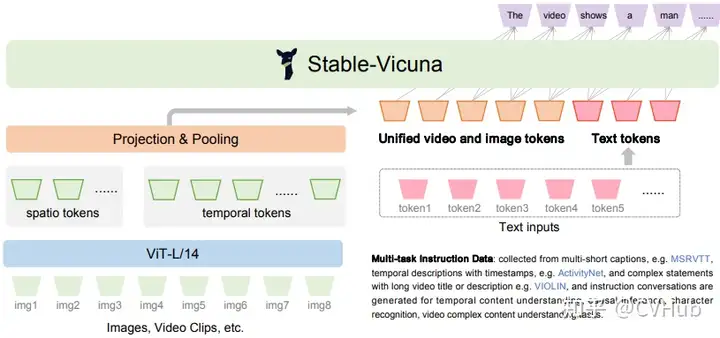
Valley: 是另一個能夠整合視頻、圖像和語言感知的多模態(tài)框架。通過使用簡單的投影模塊來橋接視頻、圖像和語言模態(tài),并通過指令調(diào)諧流水線與多語言 LLM 進(jìn)一步統(tǒng)一。
這一節(jié)主要強(qiáng)調(diào)了將不同的感知模態(tài)(如視覺、聽覺和文字)結(jié)合到統(tǒng)一框架中的重要性。通過跨模態(tài)學(xué)習(xí)和對齊,這些模型不僅提高了特定任務(wù)的性能,還擴(kuò)展了多種模態(tài)的零樣本學(xué)習(xí)能力。此外,考慮到視覺和聽覺之間的時序一致性也是重要的創(chuàng)新方向。通過強(qiáng)調(diào)如何整合這些不同的輸入形式,本節(jié)揭示了深度學(xué)習(xí)在處理更復(fù)雜和多樣化數(shù)據(jù)方面的潛力。
基于代理的基礎(chǔ)視覺模型
基于代理的基礎(chǔ)視覺模型將語言學(xué)習(xí)模型(LLMs)與現(xiàn)實(shí)世界的視覺和物理傳感器模式相結(jié)合。這不僅涉及文字的理解,還涉及與現(xiàn)實(shí)世界的互動和操作,特別是在機(jī)器人操作和導(dǎo)航方面。
機(jī)器人操控
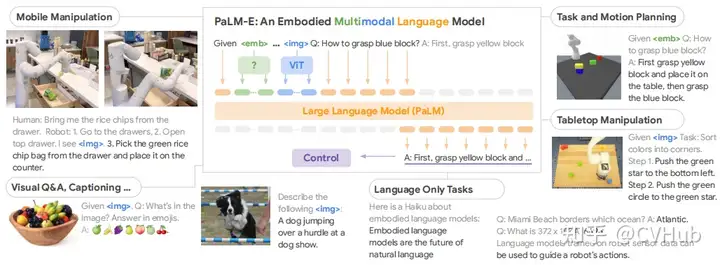
Palm-E:該模型將連續(xù)的傳感器輸入嵌入到 LLM 中,從而允許機(jī)器人進(jìn)行基于語言的序列決策。通過變換器,LLM將圖像和狀態(tài)估計等輸入嵌入到與語言標(biāo)記相同的潛在空間,并以相同的方式處理它們。
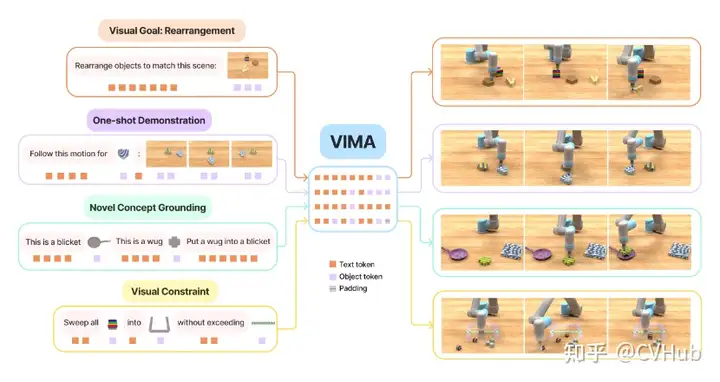
ViMA:使用文本和視覺提示來表達(dá)一系列機(jī)器人操控任務(wù),通過多模態(tài)提示來學(xué)習(xí)機(jī)器人操控。它還開發(fā)了一個包含600K專家軌跡的模擬基準(zhǔn)測試,用于模仿學(xué)習(xí)。
持續(xù)學(xué)習(xí)者
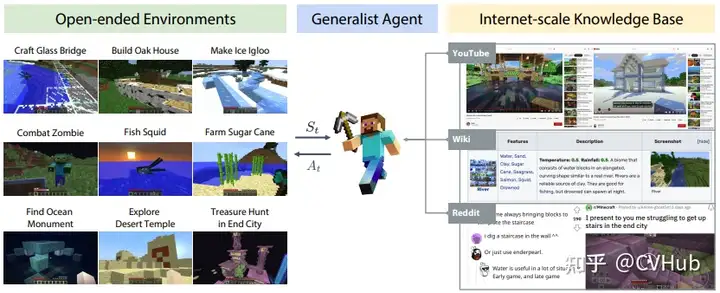
MineDojo:為 Minecraft 中的開放任務(wù)提供了便利的API,并收集了豐富的 Minecraft 數(shù)據(jù)。它還使用這些數(shù)據(jù)為體現(xiàn)代理制定了新的學(xué)習(xí)算法。
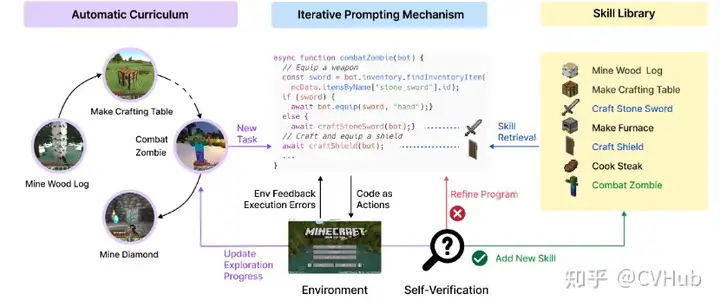
VOYAGER:這是一種由 LLM 驅(qū)動的終身學(xué)習(xí)代理,設(shè)計用于在 Minecraft 中探索、磨練技能并不斷發(fā)現(xiàn)新事物。它還通過組合較小的程序逐漸構(gòu)建技能庫,以減輕與其他持續(xù)學(xué)習(xí)方法相關(guān)的災(zāi)難性遺忘。
導(dǎo)航規(guī)劃
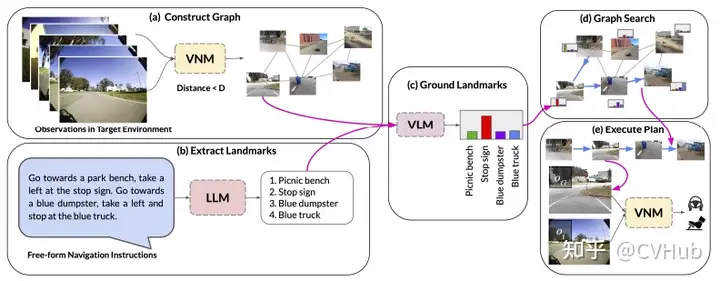
LM-Nav:結(jié)合預(yù)訓(xùn)練的視覺和語言模型與目標(biāo)控制器,從而在目標(biāo)環(huán)境中進(jìn)行長距離指導(dǎo)。通過使用視覺導(dǎo)航模型構(gòu)建環(huán)境的“心理地圖”,使用 GPT-3 解碼自由形式的文本指示,并使用 CLIP將這些文本地標(biāo)連接到拓?fù)鋱D中,從而實(shí)現(xiàn)了這一目標(biāo)。然后,它使用一種新的搜索算法找到了機(jī)器人的計劃。
總體而言,基于代理的基礎(chǔ)視覺模型突出了語言模型在現(xiàn)實(shí)世界任務(wù)中的潛力,如機(jī)器人操作、持續(xù)學(xué)習(xí)和復(fù)雜導(dǎo)航。它們不僅推動了機(jī)器人技術(shù)的進(jìn)展,還為自然語言理解、多模態(tài)交互和現(xiàn)實(shí)世界應(yīng)用開辟了新的研究方向。通過將預(yù)訓(xùn)練的大型語言模型與機(jī)器人技術(shù)和視覺導(dǎo)航相結(jié)合,基于代理的基礎(chǔ)視覺模型能夠解決現(xiàn)實(shí)世界中的復(fù)雜任務(wù),展示了人工智能的跨學(xué)科整合和應(yīng)用潛力。
需要完整 PDF 版本請?zhí)砑游⑿盘? cv_huber,備注“視覺大模型”即可領(lǐng)取!
總結(jié)
具有對多種模式(包括自然語言和視覺)基礎(chǔ)理解的模型對于開發(fā)能有效感知和推理現(xiàn)實(shí)世界的AI系統(tǒng)至關(guān)重要。今天主要為大家概括了視覺和語言基礎(chǔ)模型,重點(diǎn)關(guān)注了它們的架構(gòu)類型、訓(xùn)練目標(biāo)、下游任務(wù)適應(yīng)性和提示設(shè)計。
多模態(tài)理解:我們提供了對文本提示、視覺提示和異構(gòu)模態(tài)模型的系統(tǒng)分類。這些模型不僅涵蓋了自然語言,還包括了視覺和其他感知模式的理解。
應(yīng)用廣泛性:這些模型在各種視覺任務(wù)中的應(yīng)用非常廣泛,包括零樣本識別和定位能力、關(guān)于圖像或視頻的視覺對話、跨模態(tài)和醫(yī)療數(shù)據(jù)理解。
通用模型:視覺中的基礎(chǔ)模型可以作為通用模型來解決多個任務(wù)。當(dāng)與大型語言模型相結(jié)合時,它們促生了可以在復(fù)雜環(huán)境中持續(xù)學(xué)習(xí)和導(dǎo)航的基礎(chǔ)實(shí)體代理。
整體而言,基礎(chǔ)視覺和語言模型的研究不僅深入了解了各種架構(gòu)和訓(xùn)練目標(biāo),還展示了這些模型在多個領(lǐng)域和應(yīng)用中的潛力。通過集成文本、視覺和其他模態(tài)的理解,這些模型促進(jìn)了機(jī)器人技術(shù)和現(xiàn)實(shí)世界任務(wù)的進(jìn)展。然而,還需要進(jìn)一步的研究來充分挖掘這些模型的潛力,并解決一些存在的挑戰(zhàn)和局限性。